







本記事では、リモートリポジトリからデータを取得することができるfetchとpullの使い方と違いについて解説しています。

- 漫画形式で読みやすく理解しやすい
- GitHubを使った実践的な内容も分かりやすい

 先輩くん
先輩くんAmazon Kindle Unlimitedに登録すると、月額980円で読み放題だからオススメだよ!
初回30日間は無料だから、まだ登録したことのない人はぜひ試してみてね!
変数名/関数名にもう悩まない!

- 美しいコードが書けるが自然と書けるようになる
- 他の開発者が理解しやすいコードになる

リモートリポジトリからデータを取得する2つの方法
複数人で開発をする場合、他の開発者が作成したコードを自分のワークツリーに取り込みたい場合リモートリポジトリからデータを取得する必要があります。
リモートリポジトリからデータを取得する方法は「fetch」と「pull」の2つがあります。
fetchの使い方
fetchでリモートリポジトリのデータを取得する方法は以下の通りです。
git fetch リモート名
git merge リモート名/ブランチ名
# リモート名:origin ブランチ名:masterの場合
git fetch origin
git merge origin/masterリモート名が分からない人は、git remote -vコマンドを実行してください。
git remote -v
origin https://github.com/UserAccount/test-repository.git (fetch)
origin https://github.com/UserAccount/test-repository.git (push)行頭に表示されているものがリモート名になります。その後に続いているものはリモートリポジトリのURLです。

pullの使い方
pullでリモートリポジトリのデータを取得する方法は以下の通りです。
git pull リモート名 ブランチ名
# リモート名:origin ブランチ名:masterの場合
git pull origin masterfetchとpullの違い
fetchとpullはリモートリポジトリからデータを取得するという目的は同じですが、ワークツリーに反映させるまでのプロセスが異なります。
fetchの場合、リモートリポジトリからデータを取得したら一度ローカルリポジトリにデータを保存します。
次にローカルリポジトリに保存されたデータをワークツリーに反映させるためにmergeを行います。
pullの場合、リモートリポジトリからデータを取得したらローカルリポジトリにデータを保存しつつワークツリーにもデータを反映させてくれます。
つまり、fetchの場合ローカルリポジトリから自分でデータを取得する必要があるけど、pullの場合ローカルリポジトリからデータを取得することが不要なのでfetchよりも簡単にデータを取得することができます。
【実践】fetchとpullを使ってデータを取得する流れ
それでは実際にfetchとpullを使ってデータを取得する流れについて解説します。
ここから先の解説では、既にリモートリポジトリを作成し登録まで完了している前提で進めていくので、準備ができていない人は下記の記事を参考にリモートリポジトリの作成と登録をしてください。

GitHub上でファイルを作成する
一人でfetchやpullを使う場合、リモートリポジトリに新しいファイルを追加または編集を加える必要があるためGitHubを操作します。既に複数人開発でコマンドを試す準備が整っているひとはこの工程は省略して問題ありません。
今回は他の開発者が新規ファイルを追加したので、それを自分のワークツリーに取り込む流れで解説するので、GitHub上に新規ファイルを作成します。
GitHub上に作成したリモートリポジトリを開き「Add file → Create new file」をクリックします。
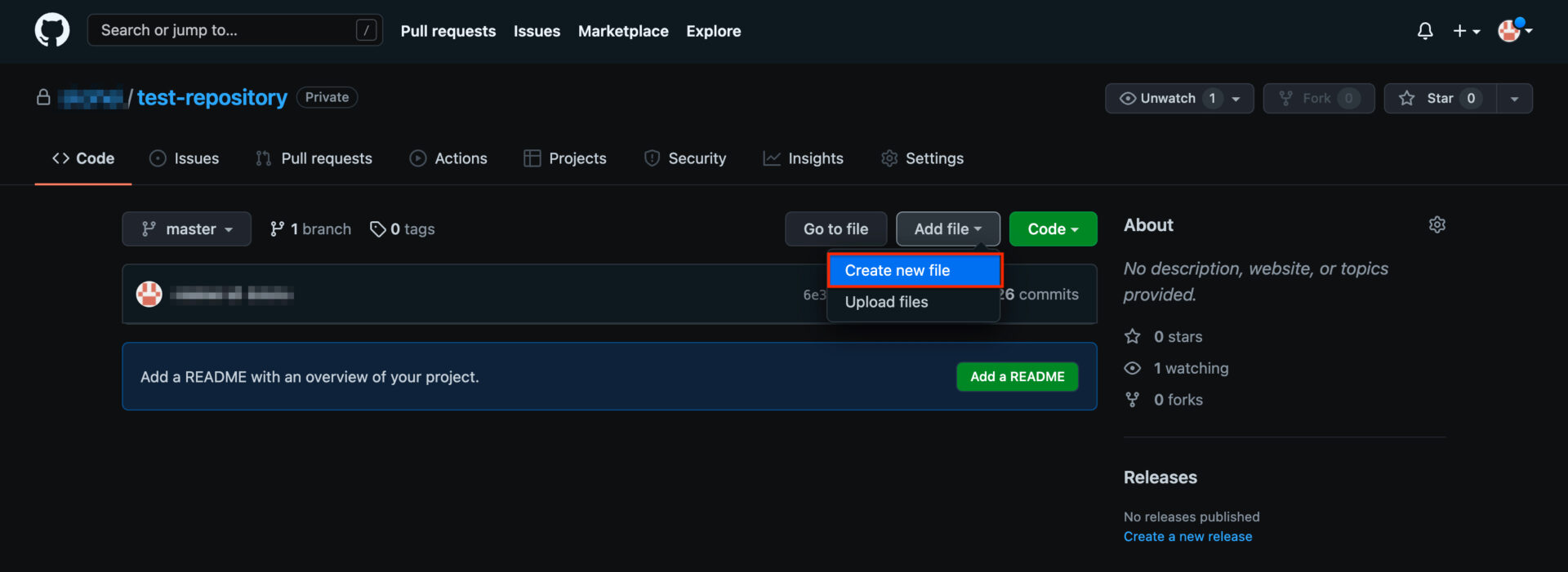
新規ファイル作成画面が表示されるので、Name your fileに「index.html」、Edit new fileに「任意のテキスト」を入力しページ下部の「Commit new file」をクリックします。
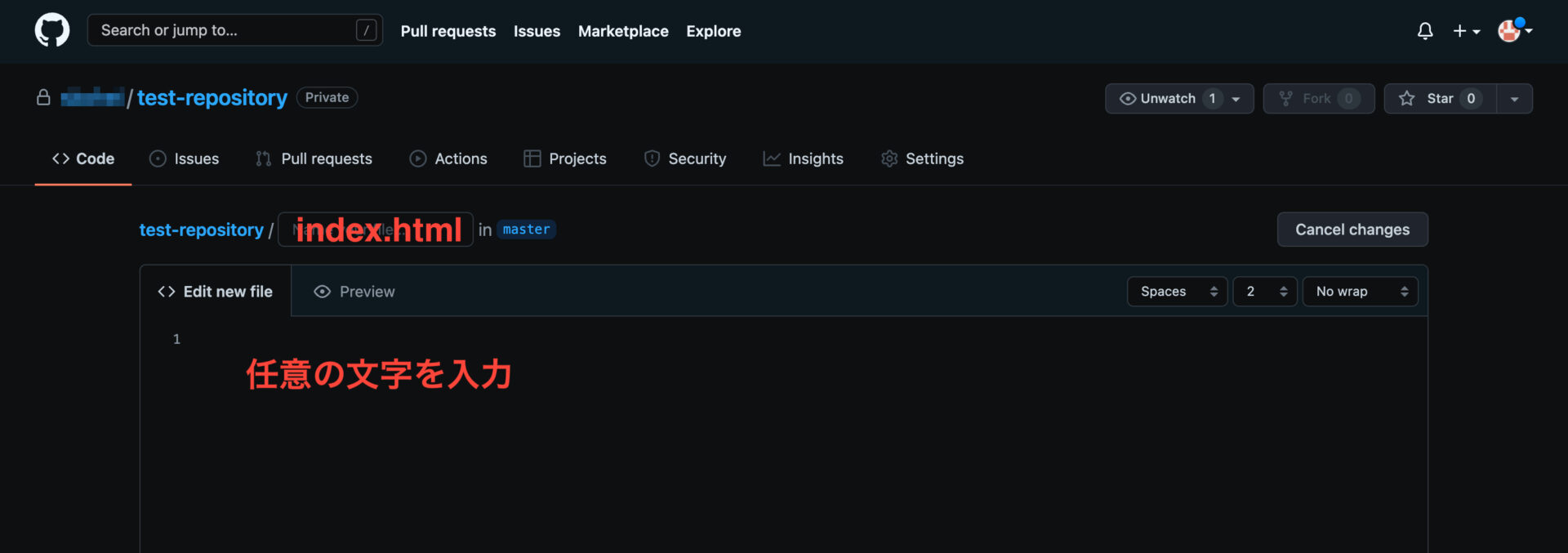
これでGitHub上に新規のindex.htmlファイルを作成することができました。
下準備は整いましたので、実際にfetchコマンドとpullコマンドを使ってデータを取得してみましょう。
fetchでデータを取得する
まず始めにgit fetch originコマンドでリモートリポジトリのデータを取得します。
git fetch origin取得してきたデータはremotes/origin/masterの中に保存されています。注意点として、リモート名をoriginではなく別の名前で設定しているひとは、登録したリモート名にデータが保存されています。
remotes/origin/masterの中身を確認してみましょう。git checkout remotes/origin/masterコマンドでリモートリポジトリのデータが保存されているブランチに切り替え、lsコマンドでファイルを確認します。
git checkout remotes/origin/master
ls
index.htmlすると、ワークツリーには存在しないindex.htmlファイルがあることが分かりました。このindex.htmlファイルは事前準備の時にGitHub上に作成したファイルです。
リモートリポジトリのデータが入っていることが確認できたので、git checkout masterコマンドでmasterブランチに戻します。
git checkout master現在の状況は、リモートリポジトリのデータをローカルリポジトリにあるremotes/origin/masterのブランチに保存しているので、これをワークツリーに反映させます。
ワークツリーに反映させるには、git merge origin/masterコマンドを実行します。
git merge origin/master最後にワークツリーに反映されているか確認するために、masterブランチでlsコマンドを実行します。
ls
index.htmlindex.htmlファイルがあることが確認できました。
以上が、fetchコマンドを使ってリモートリポジトリのデータをワークツリーに反映させる一連の流れになります。
pullでデータを取得する
fetchに比べ、pullでデータを取得する方法はとても簡単です。
git pull origin masterコマンドでリモートリポジトリからデータを取得します。
git pull origin master
Fast-forward
index.html | 1 +
1 file changed, 1 insertion(+)pullの場合、ワークツリーにもデータが反映されるためこれで作業は完了です。
最後にlsコマンドでワークツリーにリモートリポジトリのデータが反映されているか確認しましょう。
ls
index.htmlindex.htmlファイルがあることが確認できました。
以上が、pullを使ってリモートリポジトリのデータをワークツリーに反映させる一連の流れになります。
fetchとpullどちらを使うべき?
fetchとpullの違いで解説した内容と実際に触ってみて思ったことは、pullの方が簡単でいいじゃん!って思う方が多いと思います。私もその中に一人でしたから気持ちは凄く分かります。ですが、Gitに慣れていない間はfetchを使いましょう。
その理由として、pullは間違ったブランチで実行してしまうと意図しない挙動をしてしまうからです。
例えば、ワークツリーのmasterブランチでgit pull origin testコマンドを実行した場合を想定しましょう。この場合、リモートリポジトリのtestブランチの内容がワークツリー内のmasterブランチにマージされてしまいます。
git pullコマンドを使うと、このような事故が発生する可能性が高いため基本的にはfetchを使うようにしましょう。